大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据集成数据源列表PostgreSQL配置 PostgreSQL 任务
大数据研发治理套件用户指南数据集成数据源列表PostgreSQL配置 PostgreSQL 任务

PostgreSQL 数据源为您提供读取和写入 PostgreSQL 的双向通道数据集成能力,实现不同数据源与 PostgreSQL 之间进行数据传输。本文为您介绍 DataSail 的 PostgreSQL 数据同步的能力支持情况。
1 使用前提
已完成 PostgreSQL 数据源配置操作,详见配置 PostgreSQL 数据源。
2 实时整库同步(解决方案入口)
DataSail 提供独立的解决方案入口,专门用于实时整库同步场景。该入口与第 3 章的单表任务配置流程完全不同,支持全增量一体化同步,适合将 PostgreSQL 整库实时同步至 LAS、Doris、StarRocks、ByteHouse、Elasticsearch、Hudi、Paimon 等目标数据源。
2.1 前置条件(PostgreSQL 作为源端)
- PostgreSQL 数据库必须将
wal_level设置为logical,详见2.2 WAL 服务端配置(实时同步必读)。 - 已创建 publication 和逻辑复制槽,详见2.2 WAL 服务端配置(实时同步必读)的第四步。
- 需要同步的表已设置复制标识为 FULL 模式,详见2.3 复制标识设置(实时同步必读)。
- 数据源配置的用户必须拥有 SuperUser 或 replication 角色权限,详见2.1 账号与权限的授权说明。
- 已创建并绑定独享数据集成资源组,且资源组与源端、目标端网络互通。
- 目标端数据库需提前手动创建好(解决方案暂不支持自动创建数据库,仅支持自动创建表)。
- 已开通 DataLeap 项目和全域数据集成(DataSail)产品。
2.2 实时同步配置检查清单
在启动实时同步前,建议按以下清单逐项检查:
检查项 | 检查命令 | 期望结果 |
|---|---|---|
wal_level 设置 |
| logical |
max_replication_slots 充足 |
| 大于当前复制槽数量 |
max_wal_senders 充足 |
| 至少为复制槽总数的 2 倍 |
wal_sender_timeout 设置 |
| 0(已禁用) |
publication 已创建 |
| 存在目标 publication |
复制槽已创建 |
| 存在目标复制槽 |
表复制标识 |
| f(FULL 模式) |
用户权限 |
| 至少一个为 True |
磁盘空间 | 检查数据目录磁盘使用情况 | 有足够可用空间 |
2.3 配置流程
进入 DataSail 控制台,在左侧导航栏选择数据同步方案,单击新建数据同步解决方案 > 实时整库同步,按以下步骤完成配置:
- 步骤一:基本配置
- 选择链路类型(如 PostgreSQL > StarRocks)
- 填写方案名称(字母、数字、下划线、连字符,1~63 字符)
- 选择方案保存路径
- 步骤二:网络与资源配置
- 选择数据来源、数据目标的数据源
- 按需选择是否使用数据缓存(适合数据量大、对稳定性要求高的场景)
- 选择独享数据集成资源组,并测试连通性
说明
不使用缓存时,将直接采集 PostgreSQL WAL 日志。使用缓存时,需额外配置 Kafka/BMQ/DataSail 内置 Topic 数据源作为中间缓存层。
- 步骤三:资源组高级配置
- 离线全量:设置 Quota 数(需小于资源组 CU 数的一半)、期望最大并发数
- 实时增量:设置 TaskManager/JobManager 资源规格、选择镜像版本(建议选推荐标签)
- 调度设置:选择公共调度资源组或独享调度资源组
- 步骤四:映射配置
- 选择源端库表(支持指定表或正则匹配两种模式)
- 配置库/表名映射规则(同名映射或自定义)
- 配置 DDL 策略(新建表、新增列、删除列等处理方式)
- 按需配置数据转换(自定义 SQL 转换规则)
- 设置同步主键、排序策略
- 选择是否开启全量同步、配置清表策略
- 步骤五:提交方案
提交后系统自动创建全量批任务 + 增量流任务并执行
2.4 实时增量任务常用高级参数
参数名 | 默认值 | 说明 |
|---|---|---|
job.reader.poll_interval_ms | 500 | WAL 日志刷新间隔(毫秒),调小可提高实时性 |
job.reader.debezium | 无 | Debezium 配置,如忽略不可解析的 DDL |
job.common.checkpoint_interval | 900000 | Checkpoint 刷新时间(毫秒) |
job.common.is_use_batch_mode | true | true 为 Flink batch 模式(资源有限时推荐);false 为 pipeline 模式(大数据量时读写同时进行) |
job.reader.reader_parallelism_num | 自动推算 | 读并发数,默认根据数据量大小自动推算 |
job.writer.writer_parallelism_num | 自动推算 | 写并发数,默认根据数据量大小自动推算 |
2.5 方案运维
方案提交执行后,可在方案列表中进行以下运维操作:
- 执行详情:查看方案各步骤的执行状态、耗时
- 相关任务:查看实时/离线任务列表,跳转至任务运维界面
- 云监控:查看实时集成读写指标、CDC 延迟指标
- 提交执行/停止:重新启动或停止增量流任务
- 方案编辑:修改方案名称、数据来源/目标、DDL 策略、运行配置,或新增/删除同步表
- 强制重启:位点初始化、全量批任务清理并重启
- WAL 日志空间管理
WAL 日志会在 DataSail 处理后自动清理,但同步中断期间日志会持续积累。
如需紧急释放磁盘空间,可以删除复制槽(会同时清理未消费的 WAL 日志):
SELECT pg_drop_replication_slot('datasail_pgoutput_slot');建议定期调优
checkpoint_timeout和max_wal_size参数,以优化 WAL 日志管理。
完整的解决方案配置指南请参见实时整库同步(新版)。
3 离线同步任务开发
本章介绍通过数据集成入口创建的单表离线/流式同步任务的配置方式。
3.1 新建任务
PostgreSQL 数据源测试连通性成功后,进入到数据开发界面,开始新建 PostgreSQL 相关通道任务。新建任务方式详见离线数据同步、流式数据同步。
3.2 可视化配置说明
任务创建成功后,您可根据实际场景,配置 PostgreSQL 批式读、PostgreSQL 批式写或 PostgreSQL 流式写等通道任务。
3.2.1 PostgreSQL 批式读
数据来源选择 PostgreSQL,并完成以下相关参数配置:其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 PostgreSQL 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 PostgreSQL 数据源,下拉可选。若还未建立相应数据源,可单击数据源管理按钮,前往创建 PostgreSQL 数据源。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 选择需要采集的数据表名称信息,目前单个任务只支持将单表的数据采集到一个目标表中。 |
数据过滤 | 支持筛选条件设置,直接填写 where 后的过滤 SQL 语句,例如: |
切分键 | 根据配置的字段进行数据分片,建议使用主键或有索引的列。目前仅支持整型或字符串类型。 |
3.2.2 PostgreSQL 批式写
数据目标端选择 PostgreSQL,并完成以下相关参数配置:
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 PostgreSQL。 |
*数据源名称 | 已在数据源管理界面注册的 PostgreSQL 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 |
写入前准备语句 | 执行任务前率先执行的 SQL 语句,通常用于支持幂等。例如: |
写入后准备语句 | 执行任务之后执行的 SQL 语句。可视化模式下只允许配置一条。 |
*数据写入方式 | insert into:当主键/唯一性索引冲突时任务会运行失败。如果希望主键冲突时任务正常执行,可添加高级参数 |
3.2.3 PostgreSQL 流式写
支持可视化方式配置流式写入 PostgreSQL 单表。PostgreSQL Writer 通过 JDBC 远程连接 PostgreSQL 数据库,并执行相应的 SQL 语句,将数据写入 PostgreSQL。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 PostgreSQL。 |
*数据源名称 | 已在数据源管理界面注册的 PostgreSQL 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 |
3.2.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系。根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。PostgreSQL 同时也支持您在源端配置字段自定义数据类型,来满足您更复杂的数据结构或业务特定场景。
字段映射支持选择基础模式和转换模式配置映射:
注意
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
说明
来源端字段信息支持输入数据库函数和常量配置,单击手动添加按钮,在源表字段中输入需添加的值,并选择函数或常量类型,例如:
- 函数:支持您输入 now()、current_timestamp() 等 PostgreSQL 数据库支持的函数。
- 常量:您可自定义输入常量值,'123'、'${DATE}'、'${hour}' 等,输入值两侧需要加上英文单引号,支持结合时间变量参数使用。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
3.3 DSL 配置说明
PostgreSQL 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 PostgreSQL Reader 和 PostgreSQL Writer 参数脚本代码,来运行数据集成任务。
3.3.1 进入 DSL 模式
在可视化任务编辑界面,单击上方工具栏切换至脚本模式按钮,进入编辑界面。具体操作流程可参见MySQL 数据源-4.4.1 进入DSL 模式。
注意
切换脚本模式将清空现有可视化界面配置,一旦切换无法撤销。
3.3.2 PostgreSQL 批式读 DSL
以下为完整可运行的PostgreSQL 批式读脚本示例:
{ "version": "0.2", "type": "batch", "reader": { "type": "pg", "datasource_id": 12345, "parameter": { "columns": [ { "name": "id", "type": "bigint" }, { "name": "user_name", "type": "varchar" }, { "name": "create_time", "type": "timestamp" } ], "filter": "create_time > '${date}'", "split_pk": "id", "table_schema": "public", "table_name": "your_table_name" } }, "writer": { "type": "hdfs", "datasource_id": 67890, "parameter": { "columns": [ { "name": "id", "type": "BIGINT" }, { "name": "user_name", "type": "STRING" }, { "name": "create_time", "type": "STRING" } ], "path": "/your/hdfs/path/${date}", "file_type": "orc", "write_mode": "overwrite" } }, "common": { "parameter": {} } }
Reader 参数说明如下,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,对于 PostgreSQL 类型,填写:pg | 无 |
*datasource_id | 注册的 PostgreSQL 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 | 无 |
*table_schema | PostgreSQL 数据库中的 Schema 名称。 | 无 |
*table_name | 需要同步的数据表名称,目前单个任务只支持将单表的数据采集到一个目标表中。 | 无 |
filter | 同步数据的筛选条件,同步数据时只会同步符合过滤条件的数据,直接填写关键词 where 后的过滤 SQL 语句。
| 无 |
split_pk | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键,同步任务会启动并发任务进行数据同步,提高同步速率:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 | 无 |
*columns | 所配置的表中,需要同步的列名集合,使用 JSON 的数组描述字段信息。
| 无 |
3.3.3 PostgreSQL 批式写 DSL
以下为完整可运行的PostgreSQL 批式写脚本示例:
{ "version": "0.2", "type": "batch", "reader": { "type": "hdfs", "datasource_id": 67890, "parameter": { "columns": [ { "name": "id", "type": "BIGINT" }, { "name": "user_name", "type": "STRING" }, { "name": "amount", "type": "DOUBLE" } ], "path": "/your/hdfs/source/path/${date}", "file_type": "orc" } }, "writer": { "type": "pg", "datasource_id": 12345, "parameter": { "table_schema": "public", "table_name": "your_target_table", "pre_sql_list": ["delete from your_target_table where date='${date}'"], "post_sql_list": [], "write_mode": "directlyInsert", "columns": [ { "name": "id", "type": "bigint" }, { "name": "user_name", "type": "varchar" }, { "name": "amount", "type": "double precision" } ] } }, "common": { "parameter": {} } }
Writer 参数说明如下:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,对于 PostgreSQL 类型,填写:pg | 无 |
*datasource_id | 注册的 PostgreSQL 数据源 ID,可以在项目控制台 > 数据源管理界面中查找。 | 无 |
*table_schema | PostgreSQL 数据库中的 Schema 名称。 | 无 |
*table_name | 数据写入的表名。一个数据集成任务只能同步数据到一张目标表。 | 无 |
pre_sql_list | 写入前准备语句,即在执行数据集成任务前,率先执行的 SQL 语句。此语句通常是为了使任务重跑时支持幂等。 说明 DSL 模式支持配置多条写入前准备语句,多条语句之间用英文逗号分隔。 | 无 |
post_sql_list | 写入后准备语句,即执行数据同步任务后执行的 SQL 语句。例如数据写入完成后,插入某条特殊的数据,标志导入任务执行结束。 说明 DSL 模式支持配置多条写入后准备语句,多条语句之间用英文逗号分隔。 | 无 |
*write_mode | 数据导入模式,支持 insert into 模式:
| 无 |
*columns | 所配置的表中需要同步的列名集合,使用 JSON 的数组描述字段信息。
注意
| 无 |
3.4 高级参数说明
- 对于可视化通道任务,读参数需要加上
job.reader.前缀,写参数需要加上job.writer.前缀,如下图所示: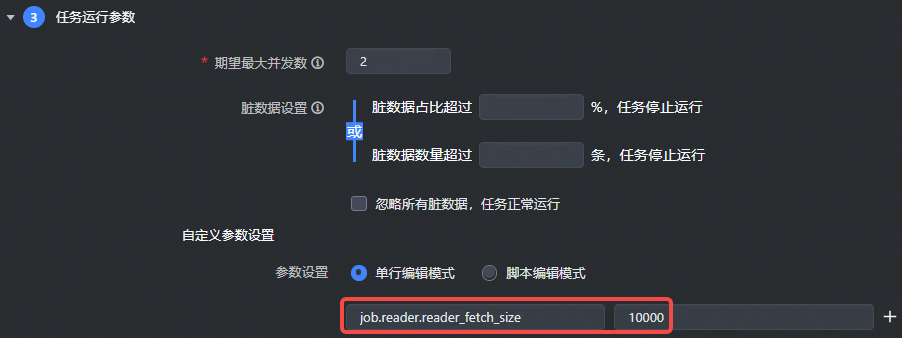
- 对于 DSL 任务,读参数请配置到
reader.parameter下,写参数请配置到writer.parameter下,直接输入参数名称和参数值。如下图所示: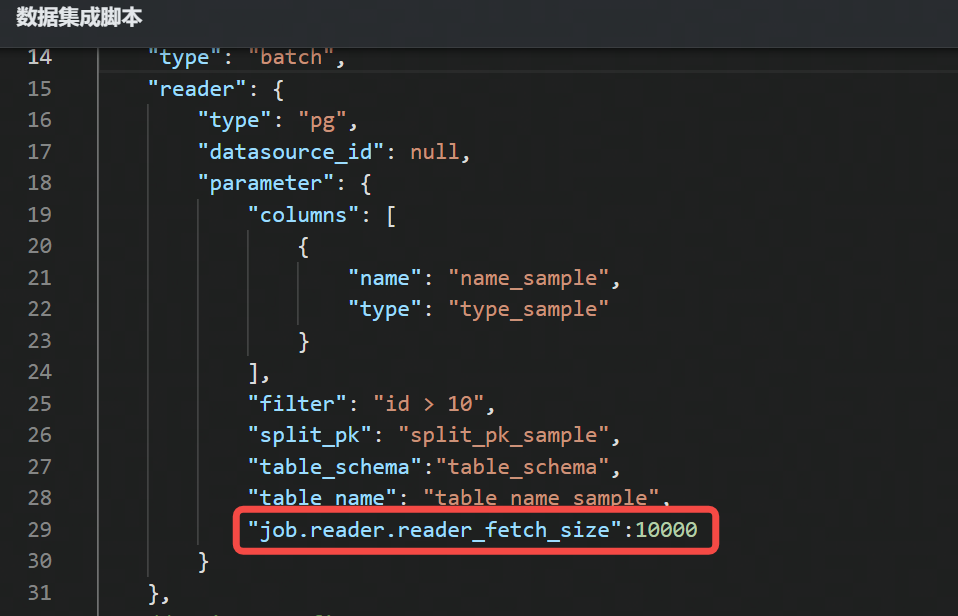
3.4.1 PostgreSQL 批式读高级参数
参数名 | 描述 | 默认值 |
|---|---|---|
init_sql | 读取数据前执行的 SQL 语句。对于视图的查询可能需要使用 init SQL 语句初始化环境。 | 无 |
reader_fetch_size | 每次拉取的数据条数,只在准确分片中有效。 | 10000 |
shard_split_mode | 分片模式,支持准确分片、并发分片、不分片三种模式:
| accurate |
customized_sql | 自定义查询读取 SQL 语句。filter 过滤配置项不足以描述所筛选的条件,可通过该配置项来自定义执行较复杂的查询 SQL。 说明 配置该高级参数项后,数据同步任务仍需配置 table_name、column 、split_pk 、shard_split_mode 等必填配置项。然而,在执行同步时,系统将忽略这些配置项信息,直接使用该高级参数项中配置的内容进行数据查询和筛选。 | 无 |
3.4.2 PostgreSQL 批式写高级参数
参数名 | 描述 | 默认值 |
|---|---|---|
is_insert_ignore | insert into 模式时,主键或唯一键冲突时任务失败还是忽略冲突。 | false |
write_batch_interval | 一次性批量提交的数据条数。设置过大可能导致 OOM。 | 100 |
write_retry_times | PostgreSQL 写入失败时重试次数 | 3 |
retry_interval_seconds | 写入失败后两次重试的时间间隔,单位秒。 | write_batch_interval / 10 |
4 最佳实践
4.1 逻辑复制 vs 查询增量
DataSail 推荐使用逻辑复制方式进行实时同步,相比基于查询的增量方式具有以下优势:
对比项 | 逻辑复制(推荐) | 查询增量 |
|---|---|---|
性能 | 直接读取 WAL 日志,对源库影响极小 | 需要执行 SQL 查询,大表时对源库有压力 |
实时性 | 秒级延迟 | 依赖调度周期(分钟~小时级) |
删除检测 | 支持自动捕获 DELETE 操作 | 需要额外配置或不支持 |
DDL 同步 | 支持(在解决方案模式下) | 不支持 |
配置复杂度 | 较高(需配置 WAL、复制槽等) | 较低 |
适用版本 | PostgreSQL 10+ | 所有支持版本 |
4.2 PostgreSQL 离线写实现幂等
对于 PostgreSQL 离线写,使用 insert into 写入方式时,重跑任务可能产生以下问题:
- 重跑失败:写入字段中包含主键或唯一键字段,任务由于 duplicate key 写入失败;
- 数据重复:写入字段中没有主键,数据重复写入。
解决方案:
- 配置写入前准备语句清空旧数据(如
delete from table_name where date='${date}'),再使用 insert into 写入。 - 使用 on duplicate key update 写入模式。
- 使用 insert into 并配置高级参数
is_insert_ignore为true。
4.3 复制槽管理
注意
未被消费的复制槽会导致 WAL 日志持续积累,占用大量磁盘空间,严重时可能导致数据库磁盘写满。
查看复制槽状态:
SELECT slot_name, active, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) AS lag_size FROM pg_replication_slots;删除不再使用的复制槽:
SELECT pg_drop_replication_slot('unused_slot_name');
建议定期巡检复制槽状态,对于 active = false 且 lag_size 持续增长的复制槽,应及时清理或排查同步任务状态。