实时音视频
实时音视频






- 文档首页
 实时音视频硬件对话智能体开始使用快速集成通过标准协议自定义接入
实时音视频硬件对话智能体开始使用快速集成通过标准协议自定义接入

除了直接使用官方 SDK,您也可以直接基于 WebSocket 标准协议自定义接入硬件对话智能体。相比于集成官方 SDK,直接对接标准协议具有更高的灵活性,但同时也要求开发者自行处理鉴权签名、连接保活、协议封装等底层逻辑。
该方式主要适用于以下场景:
- SDK 尚未支持您使用的编程语言或硬件平台。
- 希望绕过 SDK 封装,实现极致轻量化的接入。
- 需要对底层通信机制(如连接策略、数据包处理)进行深度控制或定制优化。
交互流程
本协议基于 WebSocket 实现全双工实时通信。连接建立后,客户端与服务端之间维持一条长连接,通过收发 JSON 格式的事件消息 (Events) 来完成音频流传输、状态同步及指令控制。
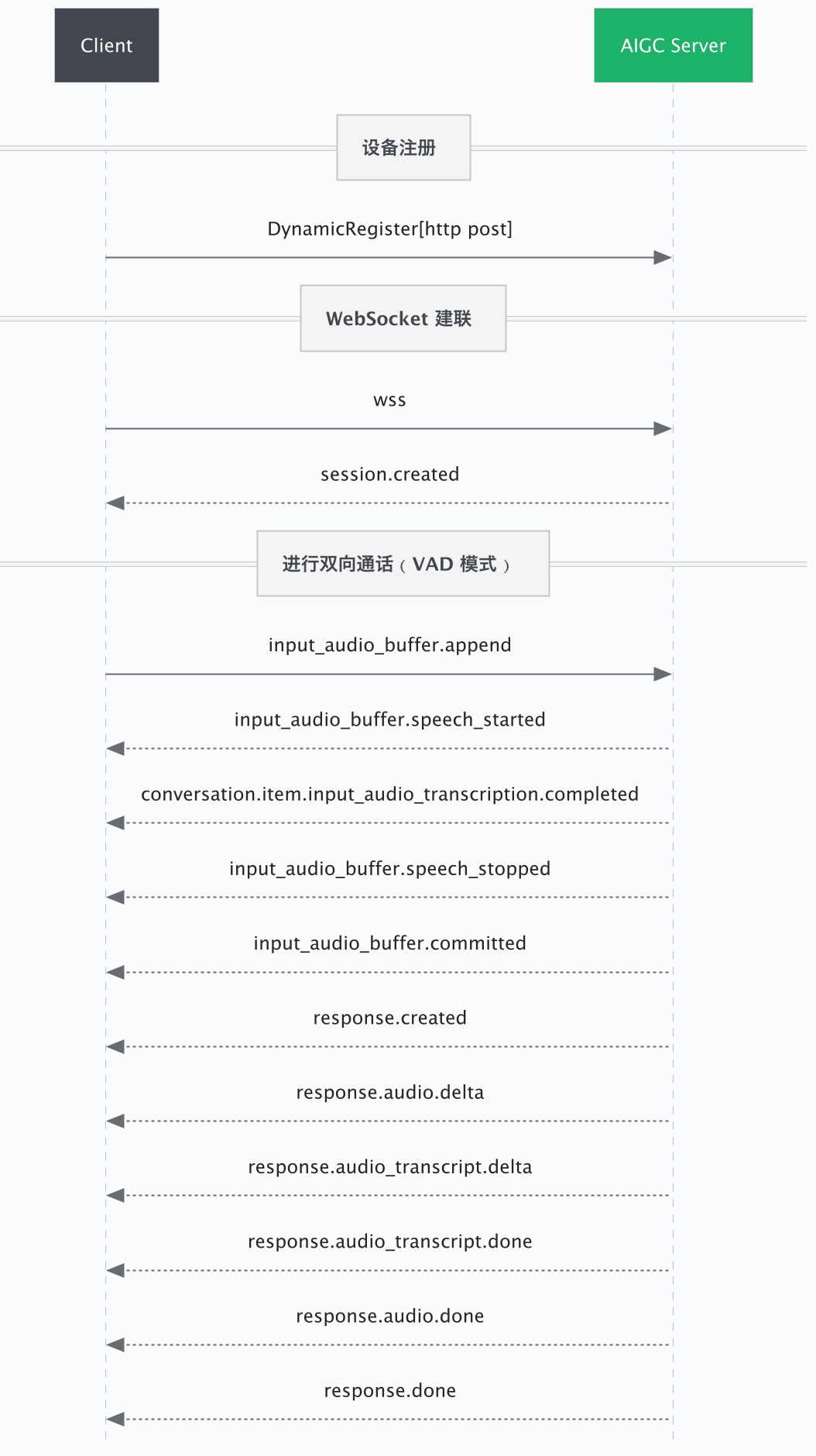
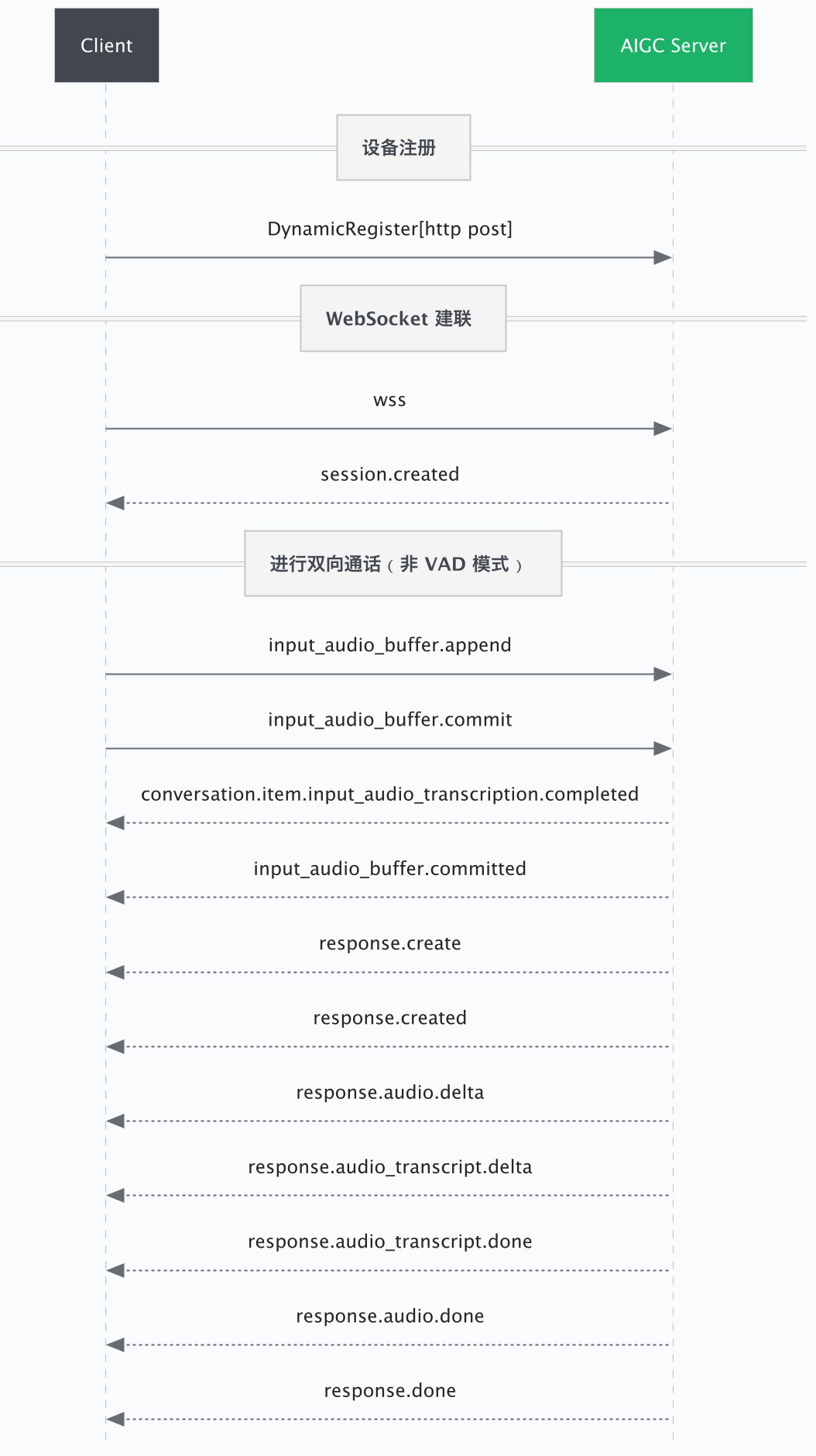
这种事件驱动的交互模式具有极低的延迟,能够支持打断、插话等模拟真实人际交流的复杂场景。根据对“说话结束”判定的主导方不同,交互流程分为以下两种模式:
VAD 模式 | 非 VAD 模式 |
|---|---|
VAD(Voice Activity Detection,语音活动检测)模式由服务端通过智能算法自动检测语音的结束,适用于需要自然、流畅对话体验的通用场景。 | 非 VAD 模式由客户端明确告知语音结束,适用于需要客户端精确控制语音结束时机的场景(如“按住说话”功能),或者设备端已集成自定义 VAD 算法的场景。 |
接入指引
准备工作
参考获取开发凭证,获取以下开发凭证:
注意
这些凭证将贯穿设备的注册与鉴权全流程,请妥善保管。
- 实例 ID (
InstanceID):物联网实例的全局唯一标识。 - 产品标识符 (
product_key):产品的全局唯一标识,用于区分不同的硬件产品类型。 - 产品密钥 (
product_secret):用于在设备注册阶段计算签名,切勿泄露或直接硬编码在客户端代码中。 - 智能体 ID (
bot_id):指定连接的具体智能体。
1. 注册设备
在首次连接前,设备端需调用DynamicRegister 设备注册接口,使用产品级密钥 (product_secret) 换取设备级独享密钥 (device_secret)。
说明
device_secret 是设备后续进行 WebSocket 鉴权连接的唯一凭证。获取后,请务必在设备端进行持久化加密存储,避免每次重启都重新注册。
2. 建立 WebSocket 连接
使用上一步获取的 device_secret 对连接参数进行签名,并通过自定义请求头 (X-Signature 等) 发起 WebSocket 连接。详细的参数构造与签名算法,请参考WebSocket 建连。
连接成功后,服务端会下发 session.created 事件,标志着会话已就绪,可以开始交互。
3. 进行双向通话
连接建立后,客户端与服务端通过收发 JSON 事件进行实时交互。客户端的核心流程如下:
上行:发送音频与控制
- 发送音频流:通过
input_audio_buffer.append事件,持续发送 Base64 编码的用户音频数据。 - 语音结束判停:
- 服务端自动检测(推荐):配置为
VAD模式(默认)。无需客户端干预,服务端会自动检测静音并截断语音。 - 客户端主动控制:配置为
非 VAD模式。由客户端(如“按住说话”按钮释放时)主动发送input_audio_buffer.commit事件,告知服务端语音结束。
- 服务端自动检测(推荐):配置为
下行:接收回复与播放
- 接收增量音频:监听
response.audio.delta事件。服务端会以流式方式下发音频数据,客户端应立即解码并播放,以降低感知延迟。 - 会话轮次结束:监听
response.done事件。该事件标志着当前轮次的所有内容(音频、文本)均已生成完毕。
4. (可选)更多高级交互
除基础的语音对话外,协议还支持更丰富的交互模式,以满足复杂的业务需求。
- 实时字幕展示
通过监听特定事件,获取对话的实时文本内容,适用于带屏设备的字幕显示。- 智能体回复:监听
response.audio_transcript.delta,实时获取回复文本的增量更新。 - 用户输入:监听
conversation.item.input_audio_transcription.completed,获取用户语音的最终识别结果。
- 智能体回复:监听
- Function Calling(端侧执行)
当智能体触发端侧函数能力(如“查询天气”、“调整音量”)时,交互流程如下:- 设备端收到
conversation.item.created事件(类型为function_call),触发函数调用。 - 设备端继续监听
response.function_call_arguments.done事件,通过匹配call_id获取完整的函数参数 (arguments)。 - 设备端解析函数调用参数,执行相应操作。
- 将执行结果封装为
conversation.item.create事件(消息类型item.type为function_call_output)发送给服务端。 - 服务端根据上报结果,生成最终的语音回复。
详细使用指导,请参见使用 Function Calling。
- 设备端收到
- 主动播报与文本提问
设备端可主动发起交互,无需用户语音唤醒。- 主动播报:当设备需要主动播报通知或引导语时,可发送
conversation.item.create(消息类型item.type为input_tts)。场景示例:设备开机欢迎语、电量不足提示。 - 文本提问:当设备需要传入文本作为用户提问时,可发送
conversation.item.create(消息类型item.type为input_text)。场景示例:用户点击屏幕上的预设问题(如“今天天气怎么样”),直接以文本形式请求智能体回答。
说明
通过
interrupt_mode参数,还可以控制上述插播内容是“立即打断当前对话”还是“排队等待当前对话结束”。 - 主动播报:当设备需要主动播报通知或引导语时,可发送
API 接口详情
本章节提供了设备注册接口、WebSocket 连接参数及所有事件消息的详细定义,供开发查阅。
DynamicRegister 设备注册
请求说明
- 请求方式 :POST
- 请求地址 :
https://iot-cn-shanghai.iot.volces.com/2021-12-14/DynamicRegister
请求参数
Query
字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
Action | string | 是 | 要执行的操作。固定为 |
Version | string | 是 | 接口版本号。固定为 |
Body
字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
InstanceID | string | 是 | 实例 ID。 |
product_key | string | 是 | 产品标识符。 |
device_name | string | 是 | 设备名,由您自定义,需确保单产品下唯一。 |
random_num | int | 是 | 随机数。 |
timestamp | uint64_t | 是 | 时间戳(Unix 格式),单位为毫秒,用于签名计算。 |
auth_type | int | 是 | 认证方式。取值固定为 |
signature | string | 是 |
|
响应参数
参数名 | 类型 | 说明 |
|---|---|---|
ResponseMetadata.Error.CodeN | int | 详见错误码。 |
ResponseMetadata.Error.Code | string | 错误标识。 |
ResponseMetadata.Error.Message | string | 错误描述信息。 |
Result.len | int | payload 长度。 |
Result.payload | string | 加密的 Device secret,使用 Base64 编码格式。
|
Result.rtc_app_id | string | RTC 的 AppID。 |
错误码
CodeN | 描述 |
|---|---|
15000010 | 产品未开始动态注册。 |
15000020 | 签名验证失败。 |
12000140 | 分配给产品的 License 已过期。 |
12000020 | 设备名称不合规,设备名称规范: |
12000130 | 分配给产品的 License 已耗尽。 |
WebSocket 建连
请求路径
wss://ai-gateway.vei.volces.com/v1/realtime
请求参数
Header
字段 | 必填 | 说明 |
|---|---|---|
X-Auth-Type | 是 | 当前设备的鉴权类型。取值固定为 |
X-Product-Key | 是 | 产品标识符,需与注册时保持一致。 |
X-Device-Name | 是 | 设备名,需与注册时保持一致。 |
X-Random-Num | 是 | 随机数。 |
X-Timestamp | 是 | 当前时间戳(Unix 格式),单位为秒,用于签名计算。 说明 此处的单位与 |
X-Instance-Id | 是 | 实例 ID,需与注册时保持一致。 |
X-Signature | 是 | 实时计算的签名串,由以下方式计算得到。
|
X-Hardware-Id | 是 | 当前设备唯一标识,建议以 MAC 地址等取值。 |
Query
字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
bot | string | 是 | 智能体 ID。 注意 必须提供与设备所属产品关联的智能体的 ID。 |
wait_for_session_update | bool | 否 | 是否等待服务端会话配置更新。
|
错误码
code | HTTP 状态码 | 描述 |
|---|---|---|
30070216 | 400 | 请求头时间戳(X-Timestamp,单位秒)非法,请检查后重试。 |
30070217 | 400 | 请求头时间戳(X-Timestamp,单位秒)过期(1分钟),请检查后重试。 |
30070300 | 500 | 内部签名错误。 |
30070301 | 401 | 签名(X-Signature)不合法,请检查 DeviceName 和 ProductKey 是否正确后重试。 |
30070302 | 504 | 请求设备信息超时,请重试。 |
30070303 | 403 | 当前设备状态下无权限访问。 |
30070304 | 400 | 请求头 X 缺失,请补全正确信息后重试。 |
30070305 | 500 | 请求设备信息失败,请提交工单联系技术支持解决。 |
30070306 | 400 | 设备不存在,请检查 DeviceName 和 ProductKey 后重试。 |
30070307 | 403 | 多个设备共享相同密钥,请保证一机一密钥后重试。 |
客户端事件
事件 | 说明 |
|---|---|
将音频字节追加到输入音频缓冲区。 | |
提交用户输入音频缓冲区,用于非 VAD 模式。 | |
清除缓冲区中的音频字节。 | |
向对话添加新项,包含文本消息、安抚语、和响应函数调用结果。 | |
指示服务器创建模型响应。 | |
取消正在进行的响应。 |
input_audio_buffer.append
将音频字节追加到输入音频缓冲区。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.append。event_id
String
本次事件 ID,需确保唯一。
audio
String
Base64 编码的音频数据。
事件示例:
{ "event_id": "event_456", "type": "input_audio_buffer.append", "audio": "Base64EncodedAudioData" }
input_audio_buffer.commit
提交用户输入音频缓冲区,用于非 VAD 模式。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.commit。event_id
String
本次事件 ID。
事件示例:
{ "event_id": "event_789", "type": "input_audio_buffer.commit" }
input_audio_buffer.clear
清除缓冲区中的音频字节。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.clear。event_id
String
本次事件 ID。
事件示例:
{ "event_id": "event_012", "type": "input_audio_buffer.clear" }
conversation.item.create
向对话添加新项,包含文本消息、安抚语、和响应函数调用结果。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
conversation.item.create。event_id
String
本次事件 ID。
item
Object
要添加到对话的项。
item.type
String
消息类型:
message:注入文本信息到 TTS 或者 LLM。function_call_output:响应函数调用结果。
item.content
array
配置文本信息。
仅当
item.type为message时为必填且生效。item.content.type
String
消息项类型:
input_text:传入文本到 LLM,主动向智能体发送文本提问。input_tts:传入文本到 TTS,让智能体播报指定文本。
item.content.text
String
注入文本内容。
item.interrupt_mode
int
处理的优先级。
仅当
item.type为message时为必填且生效。取值:
1:高优先级。智能体会终止当前交互,直接处理传入的文本内容。2:中优先级。智能体会在当前交互结束后,处理传入的文本内容。3:低优先级。如果此时智能体正在交互,智能体会直接丢弃传入的文本内容。如果未在交互,智能体会处理传入的文本内容。
item.call_id
String
函数调用 ID,必须为服务端
conversation.item.created事件中返回的item.call_id值。仅当
item.type为function_call_output时为必填且生效。item.output
String
函数调用输出内容。
仅当
item.type为function_call_output时为必填且生效。事件示例:
{ "event_id": "event_XLLz0egvR", "type": "conversation.item.create", "item": { "type": "message", "role": "user", "content": [ { "type": "input_tts", "text": "查询中请稍等" } ], "interrupt_mode": 1 } }
response.create
指示服务器创建模型响应,在"server_vad"模式下配置会话时,服务器会自动创建模型响应。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.create。event_id
String
本次事件 ID。
事件示例:
{ "type": "response.create", "event_id": "event_1718624400000" }
response.cancel
取消正在进行的响应,如果没有任何响应可供取消,服务器将以一个错误进行响应。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.cancel。event_id
String
本次事件 ID。
事件示例:
{ "type": "response.cancel", "event_id": "event_1718624400000" }
服务端事件
事件 | 说明 |
|---|---|
表示发生了错误。 | |
表示会话已成功创建。 | |
返回用户音频的转录文本。 | |
表示音频缓冲区已提交。 | |
表示音频缓冲区已清除。 | |
表示在音频流中检测到语音。 | |
表示在音频流中检测到语音结束。 | |
表示已创建新的模型响应。 | |
表示模型响应已完成。 | |
返回模型生成的增量转录文本。 | |
表示模型已完成生成转录文本。 | |
返回模型生成的增量音频数据。 | |
表示模型已完成生成音频。 | |
表示函数调用的参数已完全确定。 | |
表示已在对话中创建了一个新项(例如,函数调用)。 |
error
发生错误事件,该错误有可能是客户端或者服务端导致的。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
error。event_id
String
本次事件 ID。
error
Object
错误的详细信息。
error.type
String
错误类型。
error.code
String
错误码。
error.message
String
错误信息。
error.param
String
与错误相关的参数,如 session.modalities。
事件示例:
{ "event_id": "event_890", "type": "error", "error": { "type": "invalid_request_error", "code": "invalid_event", "message": "The 'type' field is missing.", "param": "session.modalities" } }
session.created
当客户端连接到服务端后,服务端响应的第一个事件,该事件返回时会携带服务端对此次连接的默认配置信息。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
session.created。event_id
String
本次事件 ID。
session
Object
session 的详细配置。
session.modalities
Array
模型输出模态设置,支持 ["text","audio"]。
session.model
String
本次会话用的实时模型。
session.input_audio_format
String
用户输入音频的格式。
session.output_audio_format
String
模型输出音频的格式。
session.turn_detection
Object
语音活动检测(VAD)的配置。
session.turn_detection.type
String
VAD(语音活动检测)的类型。取值固定为
server_vad,表示由服务端进行语音活动检测。事件示例:
{ "event_id": "event_T7ohkMG", "type": "session.created", "session": { "model": "doubao", "modalities": [ "text", "audio" ], "input_audio_format": "pcm16", "output_audio_format": "pcm16", "turn_detection": { "type": "server_vad" }, "temperature": 0.8 } }
conversation.item.input_audio_transcription.completed
用户音频写入用户音频缓冲区后的音频转录输出。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
conversation.item.input_audio_transcription.completed。event_id
String
本次事件 ID。
transcript
String
转录的文本内容。
事件示例:
{ "type": "conversation.item.input_audio_transcription.completed", "event_id": "event_CCXGRvtUVrax5SJAnNOWZ", "transcript": "Hi, can you hear me?" }
input_audio_buffer.committed
在 server_vad 模式下,当检测到用户说话结束时,服务端会自动提交并返回此事件。在非 server_vad 模式下,当客户端完成音频发送 input_audio_buffer.commit 事件的服务端响应时,也会返回此事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.committed。event_id
String
本次事件 ID。
事件示例:
{ "event_id": "event_15421", "type": "input_audio_buffer.committed" }
input_audio_buffer.cleared
响应客户端的 input_audio_buffer.clear 事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.cleared。event_id
String
本次事件 ID。
事件示例:
{ "event_id": "event_131764", "type": "input_audio_buffer.cleared" }
input_audio_buffer.speech_started
在 server_vad 模式下,当在音频缓冲区中检测到语音开始时,服务端会返回 input_audio_buffer.speech_started 事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.speech_started。event_id
String
本次事件 ID。
audio_start_ms
int
从音频开始写入缓冲区到首次检测到语音时的毫秒数。
事件示例:
{ "event_id": "event_157616", "type": "input_audio_buffer.speech_started", "audio_start_ms": 1000 }
input_audio_buffer.speech_stopped
在 server_vad 模式下,当在音频缓冲区中检测到语音结束时,服务端会返回 input_audio_buffer.speech_stopped 事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
input_audio_buffer.speech_stopped。event_id
String
本次事件 ID。
audio_end_ms
int
从会话开始以来,到音频输入停止时经过的毫秒数,即输入语音的时长。
事件示例:
{ "event_id": "event_17618", "type": "input_audio_buffer.speech_stopped", "audio_end_ms": 3000 }
response.created
生成新的模型响应时,服务端返回的第一个事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.createdevent_id
String
本次事件 ID。
response
Object
响应信息。
response.id
String
响应的 ID。
response.object
String
对象类型,此事件下固定为
realtime.response。response.status
String
响应的最终状态,取值固定为
in_progress。事件示例:
{ "event_id":"event_CEuTLYnzhoA5KKmaG1vIu", "type":"response.created", "response": { "id":"resp_CEuTLrWt3AhSxLPkDKgXG", "object":"realtime.response", "status":"in_progress" } }
response.done
当响应生成完成时触发,该事件中包含的 Response 对象将包含 Response 中的所有输出项,但不包括已返回的原始音频数据。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.done。event_id
String
本次事件 ID。
response
Object
响应对象。
response.id
String
响应的 ID 。
response.object
String
对象类型,此事件下固定为
realtime.response。response.status
String
响应的最终状态。取值:
completed、failed、in_progress、cancelled、incomplete。response.output
array
模式生成的内容项。
response.output.id
String
响应输出对应的 ID。
response.output.object
String
输出项的对象类型。取值固定为
realtime.item。response.output.type
String
输出项的类型。取值:
message。response.output.status
String
输出项的状态。取值:
completed、incomplete。事件示例:
{ "event_id": "event_CEuTLLSnLLvO1CiGhTdWQ", "type": "response.done", "response": { "id": "resp_CEuTKgvnLeYkDihkkMrYt", "object": "realtime.response", "status": "completed", "output": [ { "id": "item_CEuTKc8rE3zvxTx6UUYU3", "type": "message", "status": "completed", "object": "realtime.item" } ] } }
response.audio_transcript.delta
模型生成新的 audio 转录文本时触发。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.audio_transcript.delta。event_id
String
本次事件 ID。
response_id
String
响应 ID。
delta
String
增量的文本内容。
事件示例:
{ "event_id": "event_4546", "type": "response.audio_transcript.delta", "response_id": "resp_001", "delta": "Hello" }
response.audio_transcript.done
模型完成生成新的 audio 转录文本时触发。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.audio_transcript.done。event_id
String
本次事件 ID。
response_id
String
响应 ID。
transcript
String
最终的文本内容。
事件示例:
{ "event_id": "event_CEuTLxNVyy6RzzIHuYCy5", "type": "response.audio_transcript.done", "response_id": "resp_CEuTLrWt3AhSxLPkDKgXG", "transcript": "明天上海" }
response.audio.delta
模型生成新的 audio 数据时触发。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.audio.delta。event_id
String
本次事件 ID。
response_id
String
响应 ID。
delta
String
模型输出新的 audio 数据。
事件示例:
{ "event_id": "event_CEuTMuChEoBLcFYmdq6JP", "type": "response.audio.delta", "response_id": "resp_CEuTLdBQXgNZH5UrCVSuU", "delta":"Base64EncodedAudioData" }
response.audio.done
模型完成生成 audio 数据时触发。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.audio.done。event_id
String
本次事件 ID。
response_id
String
响应 ID。
事件示例:
{ "event_id": "event_CEuTNd9TaDhqnHPa2gheJ", "type": "response.audio.done", "response_id": "resp_CEuTLdBQXgNZH5UrCVSuU", }
response.function_call_arguments.done
模型生成完整的函数调用参数时触发此事件。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
response.function_call_arguments.done。event_id
String
本次事件 ID。
call_id
String
函数调用 ID。
response_id
String
响应 ID。
arguments
String
最终的函数调用参数。
事件示例:
{ "event_id": "event_CEuTLKWqM17bBedFPsCrB", "type": "response.function_call_arguments.done", "response_id": "resp_CEuTKgvnLeYkDihkkMrYt", "call_id": "call_fGwLO307ZbmckClq", "arguments": " {\"location\":\"上海\" }" }
conversation.item.created
触发 Function Calling。
事件结构:
参数
类型
说明
type
String
事件类型,该事件下固定为
conversation.item.created。event_id
String
本次事件 ID。
item
Object
要添加到对话的消息项。
item.status
String
消息项状态。
item.object
String
始终为
realtime.item。item.call_id
String
函数调用 ID。
item.type
String
消息项的类型。固定为
function_call,表示函数调用。item.name
String
调用函数名称。
事件示例:
{ "event_id": "event_CEuTLKWqM17bBedFPsCrB", "type": "conversation.item.created", "item": { "status": "in_progress", "object": "realtime.item", "call_id": "call_fGwLO307ZbmckClq", "type": "function_call", "name": "check_weather" } }