大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据集成数据源列表Kafka配置 Kafka 任务
大数据研发治理套件用户指南数据集成数据源列表Kafka配置 Kafka 任务

Kafka 数据源为您提供实时读取和离线读写 Kafka 的双向通道能力,实现不同数据源与 Kafka 数据源之间进行数据传输。
本文为您介绍 DataSail 的 Kafka 数据同步的能力支持情况。
1 使用限制
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
- Kafka 数据源目前支持可视化配置实时读取和离线读写 Kafka。
- 为确保同步任务使用的独享集成资源组具有 Kafka 库节点的网络访问能力,您需将独享集成资源组和 Kafka 数据库节点网络打通,详见网络连通解决方案。
- 若通过 VPC 网络访问,则独享集成资源组所在 VPC 中的 IPv4 CIDR 地址,需加入到 Kafka 访问白名单中。操作详见 2 使用限制
2 使用前提
已完成 Kafka 数据源配置操作。详见配置 Kafka 数据源。
3 支持的字段类型
目前支持的数据类型是根据数据格式来决定的,支持以下三种格式:
JSON 格式:
{ "id":1, "name":"demo", "age":19, "create_time":"2021-01-01", "update_time":"2022-01-01" }Protobuf(PB) 格式:
syntax = "proto2"; message pb1 { optional string a = 1; optional pb2 b = 2; optional int32 c = 3; message pb2 { optional string x = 1; repeated int32 y = 2; optional pb3 z = 3; } message pb3 { optional string j = 1; repeated int32 k = 2; } }HBASE WAL 格式。
4 新建离线任务
Kafka 数据源测试连通性成功后,进入到数据开发界面,开始新建 Kafka 相关通道任务。新建任务方式详见离线数据同步、流式数据同步。
5 可视化配置说明
任务创建成功后,您可根据实际场景,配置 Kafka 离线读、Kafka 离线写或 Kafka 流式读等通道任务。
5.1 Kafka 离线读
数据来源选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 数据来源类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic 名称 | 选择 Kafka 处理消息源的分类主题名称,下拉可选数据源下对应需读取数据的 Topic 名称。可同时选择多个,多个 Topic 结构需相同。 |
消费组 ID | 指定 Kafka 消费组 ID 信息,如果不指定该参数,则默认设定 group.id=dorado_${作业名称}_${作业id} 注意 需检查对应的 Group ID 是否存在,且 Group ID 命名规则需严格符合:dorado_{任务名称}_{任务id},否则任务会失败。 |
*数据类型 | 支持 JSON、CSV 类型,下拉可选,默认为 JSON 格式。 |
示例数据 | 数据格式为 json 时,需以 json 字符串形式描述 schema,字段映射时,支持多层级结构数据提取,如 {"address":{"city":"beijing"}},可将其提取为:address.city = beijing。 |
*分隔符 | 数据格式为 csv 时,需添加数据分隔符参数,下拉可选择原始文件的分隔符,如“,”、“Tab”、“;”等,同时也支持自定义分隔符的方式指定。 |
*周期起始位点 | 任务周期运行时,每次读取 kafka 的开始位点,即读取时间范围(左闭右开)的左边界,可通过指定时间、指定时间戳、指定位点、分区起始位点四种方式来指定周期读取的起始位点。 |
*起始时间/指定时间戳/起始位点值 | 根据选择的周期起始位点方式,可通过不同形式设置位点值:
|
*周期结束位点 | 任务周期运行时,每次读取 kafka 的结束位点,即读取时间范围(左闭右开)的右边界,可通过指定时间、指定时间戳、指定位点、分区最新位点四种方式来指定周期读取的结束位点。 |
*结束时间/指定时间戳/结束位点值 | 根据选择的周期结束位点方式,可通过不同形式设置位点值:
|
5.2 Kafka 离线写
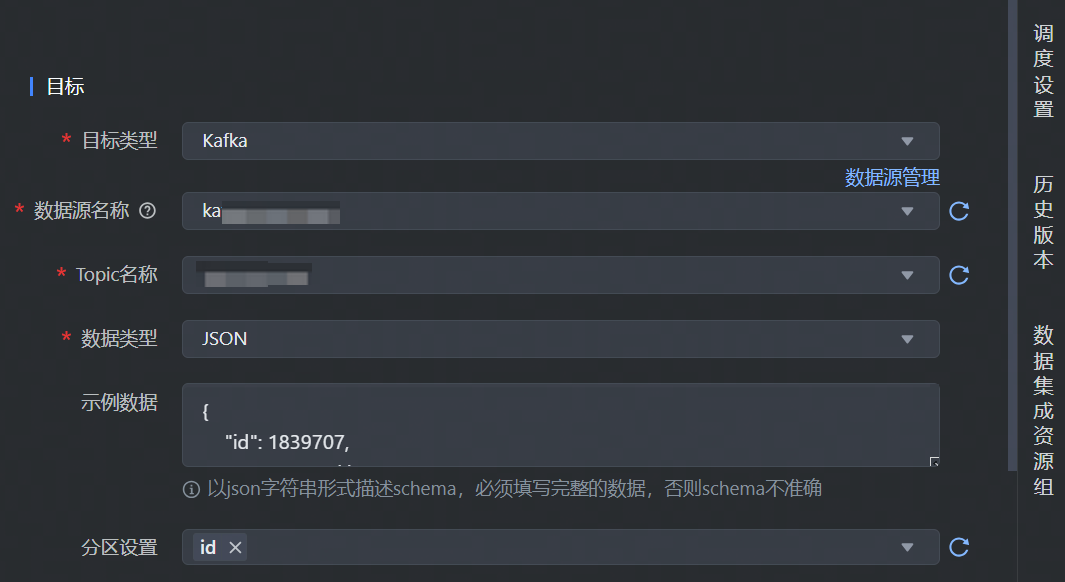
数据目标端选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic名称 | 选择 Kafka 处理消息源的不同分类主题名称,下拉可选数据源下对应需写入数据的 Topic 名称。 |
*数据格式 | 默认仅支持 json 格式,不可编辑。 |
示例数据 | 需以 json 字符串形式描述 schema。必须填写完整的数据,否则schema不准确。 |
分区设置 | 可以自定义 Kafka 分区规则,从 Kafka message 字段中选择 0~N 个字段,用于保证指定字段相同的值写入到 Kafka 的同一 partition 中。 |
5.3 Kafka 流式读
数据来源选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 数据来源类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic 名称 | 选择 Kafka 处理消息源的不同分类主题名称,下拉可选数据源下对应需读取数据的 Topic 名称,支持同时选择多个结构相同的 Topic。 |
*数据类型 | 支持 JSON、Pb、HBASE WAL,下拉可选,默认为JSON格式。 |
示例数据 | 数据格式为 json 时,需以 json 字符串形式描述 schema,支持多层级结构数据提取。 |
*Pb 类定义 | 数据格式为 Pb 时,需要先定义 Pb 类,在框中中填写 Pb 的
|
*Pb 类名 | 数据格式为 Pb 时,需要填写 PB Class 入口类名信息, |
*命名空间 | 数据类型为 HBASE WAL 时,需输入对应 Hbase 数据下存在的 namespace 空间名称。 |
*数据表 | 数据类型为 HBASE WAL 时,需填写读取的 Hbase 数据表信息。 |
5.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
字段映射支持选择基础模式和转换模式配置映射:
注意
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。同时支持选择 Kafka 元数据字段信息,字段和类型如下所示:
字段
类型
timestamp
bigint
offset
bigint
key
binary
value
binary
partition
int
headers
string
topic
string
说明
您也可通过 a.b.c 的方式,配置提取 Kafka 多层结构数据。
移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
6 DSL 配置说明
Kafka 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 Kafka Reader 参数脚本代码,来运行数据集成任务。
6.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
6.2 DSL 配置 Kafka 流式读
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,Kafka 流式读脚本示例如下:
{ "version": "0.2", "type": "stream", "reader": { "type": "kafka_volc", "datasource_id": null, "parameter": { "connector":{ "connector":{ "owner":"Account/xxxxxx", "topic":"topic_name", "startup-mode":"latest-offset", "bootstrap":{ "servers":"kafka-cnxxxxxxrk.kafka.ivolces.com:9092" }, "group":{ "id":"group_id_test" } }, "update-mode":"append" }, "child_connector_type":"kafka220", "columns": [ { "upperCaseName": "ID", "name": "id", "type": "BIGINT" }, { "upperCaseName": "NAME", "name": "name", "type": "VARCHAR" }, { "upperCaseName": "PRICE", "name": "price", "type": "DOUBLE" }, { "upperCaseName": "LIST_INFO", "name": "list_info", "type": "VARCHAR" }, { "upperCaseName": "EVENT_TIME", "name": "event_time", "type": "BIGINT" }, { "upperCaseName": "ADDRESS", "name": "address", "type": "VARCHAR" }, { "upperCaseName": "MAP_INFO", "name": "map_info", "type": "VARCHAR" }, { "upperCaseName": "CREATE_TIME", "name": "create_time", "type": "BIGINT" } ], "enable_source_parser": "true", "class":"com.bytedance.dts.dump.dataplugin.source.mq.Kafka020SourceFunctionDAGBuilder" } }, "writer": { "type": "hbase", "datasource_id": null, "parameter": { "hbase_conf":{ "hbase.zookeeper.quorum":"hb-cxxxxxx-zk.config.config.volces.com:2181", "hbase.zookeeper.property.clientPort":"2181", "zookeeper.znode.parent":"/hbase/hb-cxxxxxxx7e", "hbase.rootdir":"/hbase/hb-cxxxxxxx7e", "hbase.cluster.distributed":true }, "format.type":"json", "columns":[ { "upperCaseName":"CF:ID", "name":"cf:id", "type":"bigint" }, { "upperCaseName":"CF:NAME", "name":"cf:name", "type":"string" }, { "upperCaseName":"CF:PRICE", "name":"cf:price", "type":"double" }, { "upperCaseName":"CF:LIST_INFO", "name":"cf:list_info", "type":"string" }, { "upperCaseName":"CF:EVENT_TIME", "name":"cf:event_time", "type":"bigint" }, { "upperCaseName":"CF:ADDRESS", "name":"cf:address", "type":"string" }, { "upperCaseName":"CF:MAP_INFO", "name":"cf:map_info", "type":"string" }, { "upperCaseName":"CF:CREATE_TIME", "name":"cf:create_time", "type":"bigint" } ], "class":"com.bytedance.dts.batch.hbase.HBaseOutputFormat", "table":"default:hbase_xxxxxxxtest_one", "row_key_column":"$(cf:id)", "writer_parallelism_num":2 } }, "common": { "parameter": { "optional":{ // 高级参数输入,格式如 "key" : "value" (must be string) "global_parallelism_num": 1, "dirty_record_skip_enabled": "false", "checkpoint_interval": 180000 } } } }
Kafka 流式读参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 参数说明 | 样例&详细说明 |
|---|---|---|
*datasource_id | 注册的 Kafka 数据源 ID。可以在项目控制台 > 数据源管理界面中查找 | 若通过 Kafka 连接串信息配置时,可以不填 datasource_id 信息,将其设置为 null |
*topic | Kafka 消费的 topic 列表,可填写多个 topic,用英文逗号隔开 | topic1,topic2,toipic3 |
owner | 配置任务 owner 的账号信息 | Account/21xxxxxx57 |
startup-mode | 配置任务初始消费策略 | 默认:group offset 开始消费 |
bootstreap.servers | 填写 Kafka 连接串信息 | 若配置了 datasource_id 时,则可以忽略不填 |
version | Kafka broker 版本 | |
group.id | Kafka 中 group id 信息 | 若不填时,会默认按照任务名称和任务 id 拼接而成 |
update-mode | 消息更新模式 | Kafka 一般情况下配置为:append |
*child_connector_type | Kafka connector 类型 | kafka connector 一般情况下配置为:kafka220 |
*columns | kafka 消息中的字段名称及类型信息 | |
enable_source_parser | 是否用在 source 端解析消息 | kafka 场景一般为 true |
*class | 使用引擎内 kafka 的类名,有明确指定 datasource_id 后,可以忽略不填 | Kafka 需配置为: |
6.3 DSL 配置 Kafka 离线读
根据实际情况替换 Kafka 流式读相应参数,Kafka 流式读脚本示例如下:
// ************************************** // Author: DataLeapTest1 // CreateTime: 2024-03-12 14:46:29 // Description: // Update: Task Update Description // 变量使用规则如下: // 1.自定义参数变量: {{}}, 比如{{number}} // 2.系统时间变量${}, 比如 ${date}、${hour} // ************************************** { // [required] dsl version, suggest to use latest version "version": "0.2", // [required] exection mode, supoort streaming / batch now "type": "batch", // reader config "reader": { // [required] datasource type "type": "kafka" , // [optional] datasource id, set it if you have registered datasource "datasource_id": 6xxx4, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // schema // "reader_parallelism_num":1, "kafka_servers":"kafka-cnxxxxxxrk.kafka.ivolces.com:9092", "content_type":"csv", "csv_delimiter":"|", "metadata_columns": "__timestamp__,__offset__,__value__", "columns":[ { "name":"__value__", "type":"string" }, { "name":"__timestamp__", "type":"bigint" }, { "name":"__offset__", "type":"bigint" }, { "upperCaseName":"ID", "name":"id", "type":"bigint" }, { "upperCaseName":"NAME", "name":"name", "type":"string" }, { "upperCaseName":"PRICE", "name":"price", "type":"double" } ], "topics":"topic_namq", "group_id":"groupname_test", // "start_timestamp": 1710407869000, // "end_timestamp": 1710408169000, // or start/end date format "start_date": "${DTF-yyyyMMddHHmmss-15i}", "end_date": "${DTF-yyyyMMddHHmmss}", "date_format": "yyyyMMddHHmmss", "class":"com.bytedance.bitsail.connector.kafka.source.KafkaSubscribeSource" } }, "writer": { // [required] datasource type "type": "hive" , // [optional] datasource id, set it if you have registered datasource "datasource_id": 66703, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // schema "class":"com.bytedance.dts.batch.hive.parquet.HiveParquetOutputFormat", "hive_version":"3.1.2", "emr_hive_conf": { "hive.metastore.uris": "thrift://xxx.xx.x.xx:9083,thrift://xxx.xx.x.xx:9083,thrift://xxx.xx.x.xx:9083" }, "db_name": "db_name_test", "table_name":"table_name_test", "partition": "date=20240312,hour=24", "columns": [ { "name":"meta_value", "type":"string" }, { "name":"meta_timestamp", "type":"bigint" }, { "name":"meta_offset", "type":"bigint" }, { "name": "id", "type": "bigint" }, { "name": "name", "type": "string" }, { "name": "price", "type": "double" } ] } }, // common config "common": { // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // [optional] advanced parameters "optional": { // 高级参数输入,格式如 "key" : "value" (must be string) } } } }
Kafka 离线读参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
说明
消费开始时间,可用时间戳或时间字符串形式填写,即表格中,您可选择填写 start_timestamp、end_timestamp 组合或 start_date、end_date 组合。
reader参数 | 参数说明 | 样例&详细说明 |
|---|---|---|
*kafka_servers | Kafka 连接串信息,输入的连接串信息需保证和独享集成资源组的网络连通性。配置 datasource_id 信息时,连接串信息可忽略不填。 | kafka-cnxxxxxxrk.kafka.ivolces.com:9092 |
*content_type | Kafka 消息格式,支持填写 csv、json 格式。 |
|
*csv_delimiter | 若 Kafka 消息格式为 csv 时,您需指定 csv 格式分隔符。 | |
*metadata_columns | 指定拉取 kafka 的元数据字段。 | timestamp,offset,... 说明
|
*columns | kafka 消息中的字段类型。 | 每个field以分隔符分出来的顺序对应 |
*topics | Kafka 消费的 topic 列表,可填写多个 topic,用英文逗号隔开。 | topic1,topic2,toipic3 |
*group_id | Kafka consumer group id | |
start_timestamp | 消费开始时间戳 (单位:毫秒),指定 start_date 参数后可以不用填写。 | |
end_timestamp | 消费结束时间戳(单位:毫秒),指定 end_date 参数后可以不用填写。 | |
start_date | 消费开始时间字符串,支持以时间变量形式填写,根据任务配置的调度时间,执行时解析成具体的时间,如 ${DTF-yyyyMMddHHmmss-15i},更多时间变量参数详见平台时间变量与常量说明 | 时间变量表达式:${DTF-yyyyMMddHHmmss-15i} ,实际执行时表达式解析为202403172345 (2024年03月17日23点45分) |
end_date | 消费结束时间字符串,同样支持以时间变量形式填写。 | 时间变量表达式:${DTF-yyyyMMddHHmmss} ,实际执行时表达式解析为202403180000 (2024年03月18日00点00分) |
date_format | 时间字符串格式 | yyyyMMddHHmmss ,支持配置到分钟级别的时间格式串,可自定义其他的时间格式串,详见平台时间变量与常量说明 |
*class | 固定值,保持不变 | com.bytedance.bitsail.connector.kafka.source.KafkaSubscribeSource |
7 流式任务运行参数说明
7.1 运行参数说明
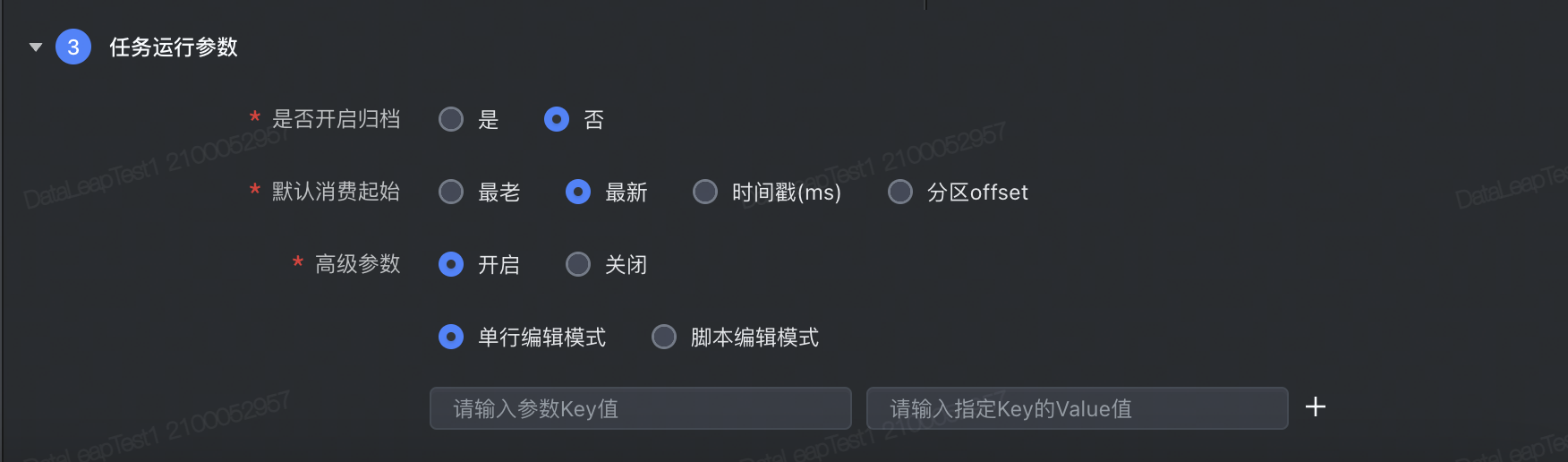
流式任务运行参数与离线任务运行参数配置属性不同,下面将为您介绍流式任务运行参数配置说明:
配置项 | 说明 |
|---|---|
是否开启归档 | 默认否,这个选项只有在目标数据源是
|
默认消费起始 | 选定消费 Kafka 的起始方式:
|
高级参数 | 读参数需要加上 |
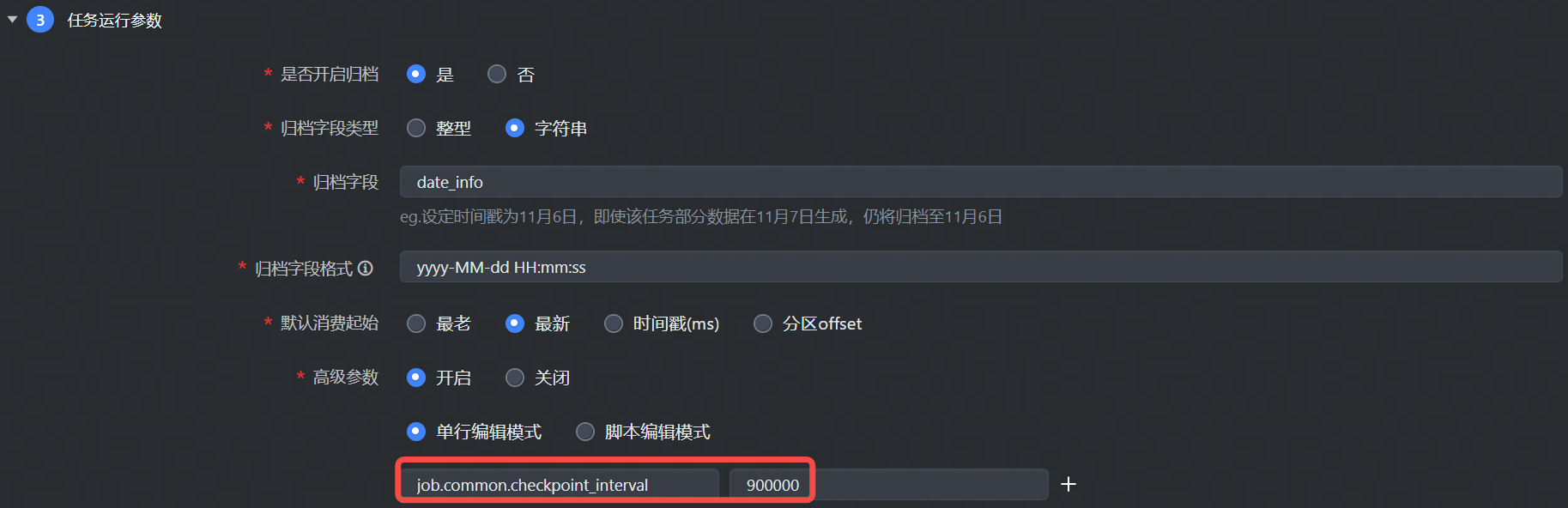
7.2 高级参数列表
参数名 | 描述 | 默认值 |
|---|---|---|
job.common.checkpoint_interval | checkpoint 的间隔,目前默认 15min 会进行一次 checkpoint。 | 900000,单位 ms |
job.common.checkpoint_timeout | Checkpoint 超时时间。 | 300000,单位:milliseconds |
job.common.host_ips_mapping | Kafka 通过公网接入,kafka broker 设置为域名;需配置 ip 与域名映射,示例如下: | |
job.reader.connector.startup-mode | 默认消费起始位置参数指定:
| |
job.reader.metadata_columns | 读取 Kafka 元数据相关信息,多个元数据可用英文逗号隔开。配置示例如下:job.reader.metadata_columns = timestamp,offset,key,value,partition,headers | |
job.writer.properties | 写入 buffer 数据大小设置:
说明 适用范围:DataSail 整库解决方案配置中,如果单个消息体比较大时,可以调整此参数。 | {"max.request.size":1048576,"buffer.memory":33554432} |
job.common.optional | 写入 buffer 数据大小设置,默认 1048576:
| {"max.request.size":1048576,"buffer.memory":33554432} |
job.writer.compression_type | 消息压缩格式,支持 none、snappy、gzip、lz4 说明 DataSail 整库解决方案配置中,可指定消息压缩格式。 | snappy |
job.common.skip_dump_parse | Kafka 数据源通过公网形式接入,开启 SASL_SSL 认证时,需设置该参数为 true。 | false |
job.writer.case_insensitive | 如有大小写转换问题,建议配置为大小写敏感即 job.writer.case_insensitive=false。 | true |
job.reader.connector.connector.group_id | 输入消费 kafka group_id ,如不指定时,则会根据”任务名和任务ID“等信息拼接生成一个。 | 无 |
job.reader.connector.connector.kafka.properties.receive.buffer.bytes | 该参数可指定消费者在接收消息时用于存储网络数据的缓冲区的大小(以字节为单位),调大这个参数可以提高数据接收效率,但也要考虑内存使用的平衡。 | 65536 |
job.reader.connector.connector.kafka.properties.max.partition.fetch.bytes | 该参数指定消费者每次从单个分区拉取的最大字节数。默认值为 1 MB(1048576 字节)。 | 1048576 |
job.reader.connector.connector.kafka.properties.max.poll.records | 该参数可指定每次调用
参考建议:20000 | 500 |