大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据开发LASLAS Spark
大数据研发治理套件用户指南数据开发LASLAS Spark

LAS Spark 任务适用于定时执行 Spark 离线任务的场景,支持 Jar 包资源和 Python资源引用的方式。
1 使用限制
LAS ByteLake 表的属性不支持并发写入数据,否则会出现写入冲突情况。通过 Spark 任务在向 ByteLake 表写入数据时,您可在 DataLeap 任务调度设置里,开启最大并发控制按钮,并将其设置为 1,以此避免因实例并发冲突致使任务执行失败。此外,您还需确保在其他业务中不存在并发写入同一个 ByteLake 表的情况。
2 使用前提
- 已开通湖仓一体分析服务 LAS 服务。详见湖仓一体分析服务 LAS 开通。
- 已在 DataLeap 项目控制台中,绑定相应的 湖仓一体分析服务(LAS)引擎实例。详见创建项目。
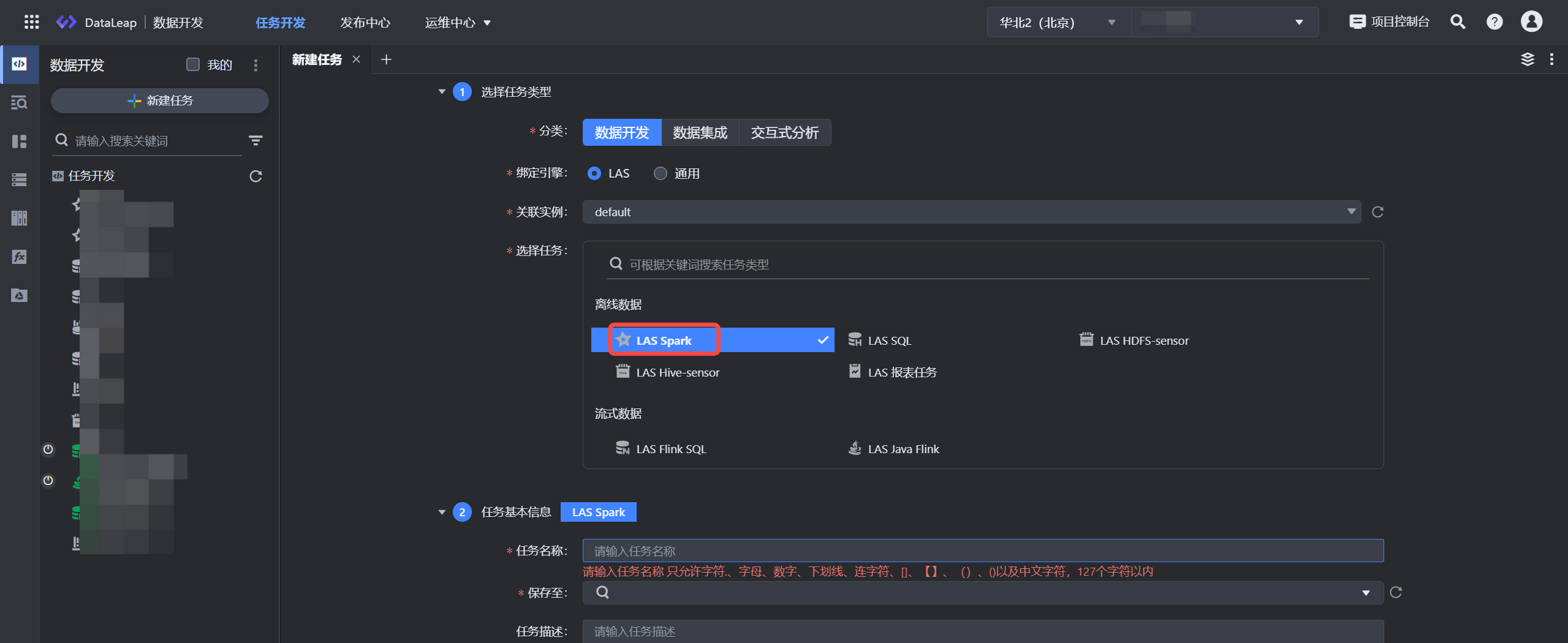
3 新建任务
- 登录 DataLeap租户控制台,并进入项目的 IDE 开发界面,进行新建任务操作。
- 单击新建任务按钮:
- 依次选择数据开发 > LAS > LAS Spark 任务类型。
- 关联实例:默认选择项目已绑定的 default 实例。绑定详见创建项目。
- 填写任务基本信息,输入任务名称信息,如:las_spark_task,并选择任务存放的目标文件夹目录。单击确定按钮,完成任务创建。
注意
- 在项目控制台管理界面中,如果新增或修改了引擎,那么在数据开发任务新建窗口中,需刷新整个 DataLeap 数据开发界面,才能看到新增或修改后的引擎任务类型。
- 任务名称信息仅允许字符.、字母、数字、下划线、连字符、[]、【】、()、()以及中文字符,且需要在127个字符以内。
4 任务配置说明
新建任务完成后,在任务配置界面完成以下参数配置。
4.1 语言设置
语言类型支持 Java、Python。
说明
语言类型暂不支持互相转换,切换语言类型会清空当前配置,需谨慎切换。
4.2 引入资源
语言类型选择 Java 时,资源类型支持 Jar 资源包的形式,可以按以下方式选择资源:
- 从资源库选取已有的 jar 资源
- 新建资源,详见:资源库。
语言类型选择 Python 时:
- 资源类型默认选择 Python 类型,且需选择资源所关联的 LAS Schema 库信息。
- 在编辑器中输入 Python 语句,执行引擎只支持 Python3.7。示例脚本如下:
from pyspark import SparkFiles from pyspark.sql import SparkSession from pyspark.sql import SQLContext job_name='pyspark_test_on_las' spark = SparkSession.builder.appName(job_name).getOrCreate() spark.sql("select 1").show(10) spark.stop()更多 LAS Spark 任务操作,详见:Spark JAR 开发。
注意
若语句中需要设置系统环境变量时,避免直接覆盖系统环境变量,请按照追加方式指定,例如PATH=$PATH:/home/lihua/apps/bin/;
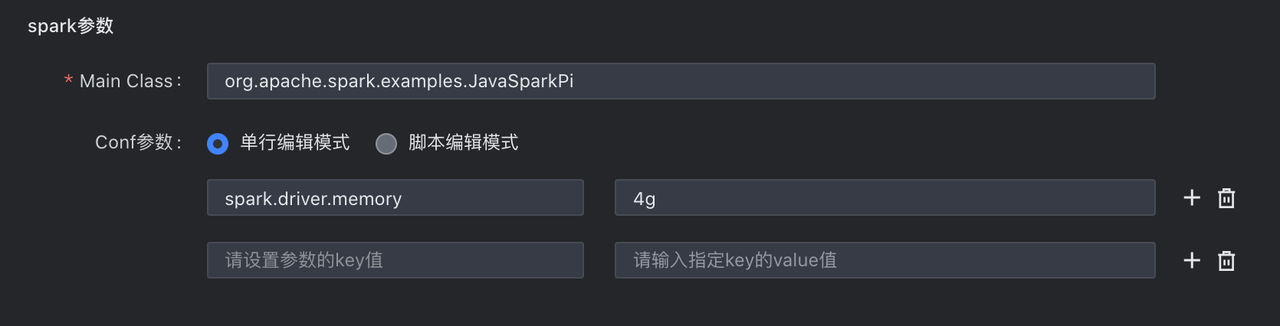
4.3 参数配置
参数 | 说明 |
|---|---|
Spark 参数 | |
Main Class/Py-files |
|
Conf参数 | 配置任务中需设置的一些 conf 参数,如常用的 Driver 内存分配参数
|
任务参数 | |
自定义参数 | 输入任务中需要额外传递的参数,如数据输入/输出路径参数、数据处理的业务时间参数、过滤条件参数等等。
|
4.4 任务产出登记
任务产出数据登记,用于记录任务---数据血缘信息,并不会对代码逻辑造成影响。对于系统无法通过解析获取产出信息的任务,可手动登记其产出信息。
如果任务含有 LAS 表的写入操作,强烈建议填写。您填写的内容即为任务产出,支持填写多个。其他任务的依赖推荐会根据此处填写的 LAS 表信息进行推荐。 具体登记内容包括:
- 数据类型:选择 LAS 时,需下拉选择当前任务写入数据的 LAS 数据库和数据表信息。
- 其他:该任务不写数据到 LAS 表。
5 使用示例
以下示例将为您演示如何通过 LAS Spark 任务中 Python 语言方式,来直接访问 LAS 表中的数据。
5.1 数据准备
- 新建 LAS SQL 作业,操作详见:LAS SQL。
- 在代码编辑区,编辑并执行以下示例语句,创建 LAS 示例表,并将数据写入表中:
CREATE TABLE IF NOT EXISTS test_schema.student_demo ( id INT COMMENT 'id', name STRING COMMENT 'name', age INT COMMENT 'age' ) PARTITIONED BY (date STRING COMMENT 'date partition') stored as bytelake; INSERT INTO test_schema.student_demo PARTITION (date = '20230518') VALUES(1, 'TOM', 10);
5.2 配置 LAS Spark 任务
- 新建 LAS Spark 任务,详见上方新建任务。
- 进入任务配置界面,语言类型选择 Python。
- 选择库表资源所需关联的 LAS Schema 库信息:test_schema。
- 在代码编辑区域,编辑以下相关 Python 查询语句:
说明
LAS ByteLake 2.0 和 Managed Hive 表类型,推荐使用以下 lasfs 示例;对于 ByteLake1.0 内表,需继续使用 Tunnel 方式。详见 Spark Jar 作业开发。
from pyspark import SparkConf from pyspark.context import SparkContext from pyspark.sql import SparkSession, SQLContext SparkContext._ensure_initialized() spark = SparkSession.builder \ .appName("pyspark_test_read_hive_x_new_1") \ .config("spark.sql.lasfs.enabled", "true") \ .config("spark.hadoop.hive.exec.scratchdir", "lasfs:/warehouse/tmp/hive") \ .config("spark.hadoop.tmp.dir", "lasfs:/warehouse/tmp/hadoop") \ .config("spark.hadoop.fs.lasfs.impl", "com.volcengine.las.fs.LasFileSystem") \ .config("spark.hadoop.fs.lasfs.endpoint", "100.96.4.84:80") \ .config("spark.hadoop.fs.lasfs.service.region", "cn-beijing") \ .config("spark.hadoop.fs.lasfs.access.key", "AKxxx") \ .config("spark.hadoop.fs.lasfs.secret.key", "SKxxx==") \ .config("spark.sql.analysis.hoodie.relation.conversion.skip.enabled", "false") \ .config("spark.sql.extensions", "org.apache.spark.sql.LASExtension") \ .enableHiveSupport() \ .getOrCreate() sc = spark.sparkContext sql = spark.sql sqlContext = spark._wrapped sqlCtx = sqlContext df = sql("insert into test_schema.student_demo partition (date='20240619') values('1','TOM','10')") df.show() spark.stop()
替换参数说明:
参数
说明
appName
自定义 Spark 任务名称。
access.key
可前往访问控制的密钥管理中查看 Access Key ID。相关操作说明请参见 Access Key(密钥)管理。
secret.key
可前往访问控制的密钥管理中查看 Secret Access Key。相关操作说明请参见 Access Key(密钥)管理。
endpoint
需按照您所在的 Region 信息进行配置,不同地域值,详见 Spark Jar 作业开发 - spark.hadoop.fs.lasfs.endpoint。
region
按照您所在的 Region 信息,对应配置:
- 华北region:cn-beijing
- 华东region:cn-shanghai
- 华南region:cn-grougzhou
- 柔佛region:ap-southeast-1
5.3 调试运行
任务配置完成后,您可单击操作栏中的保存和调试按钮,进行任务调试。
注意
- 调试操作,直接使用线上数据进行调试,需谨慎操作。
- 数据开发界面调试日志数据,保留 15 天,您可在 15 天内查看相应的调试日志详情。
- 本任务类型支持调试执行成功或失败后发送消息通知给调试发起人,您可根据业务情况,前往项目控制台 > 配置信息 > 消息通知设置中,选择是否开启任务调试运行成功或失败通知。默认通知方式为邮箱,调试发起人需在火山引擎“访问控制 > IAM 用户详情”中,提前绑定相应的安全邮箱信息;
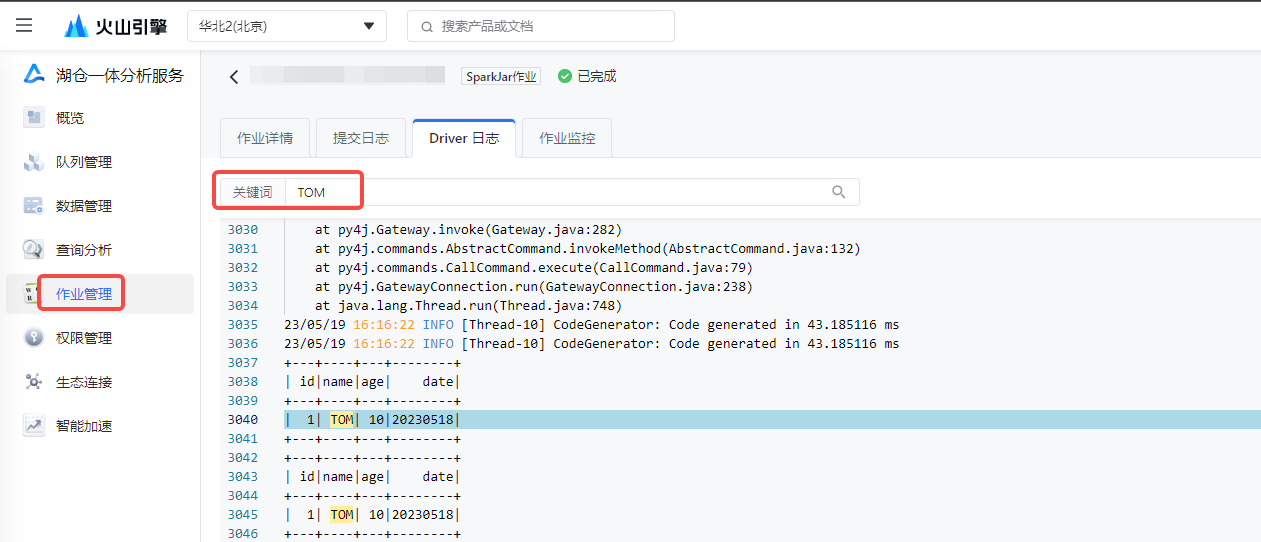
5.4 查看日志
待任务执行成功后,您可进入火山引擎控制台:
- 搜索访问 LAS 服务,单击进入 LAS 控制台 > 作业管理 > SparkJar 作业界面。
- 在作业列表界面,单击右侧操作列中的日志按钮,进入到 SparkJar 作业详细日志界面。
- 单击 Driver 日志页签,并搜索数据关键字信息,从日志中查看 LAS 表数据查询结果。
6 提交任务
调试任务成功,并查看日志校验数据情况无误后,返回数据开发界面,将任务提交发布到运维中心离线任务运维中执行。
单击上方操作栏中的保存和提交上线按钮,在提交上线对话框中,选择回溯数据、监控设置、提交设置等参数,最后单击确认按钮,完成作业提交。 提交上线说明详见:数据开发概述---离线任务提交。
后续任务运维操作详见:离线任务运维。